Machine Vision
Text Detection Algorithms: How to Find Text in Images
Learn how this algorithm effectively detects and extracts text from images, enabling image understanding and analysis.
Learn how this algorithm effectively detects and extracts text from images, enabling image understanding and analysis.

Extracting text from images, known as Optical Character Recognition (OCR), often involves a series of image processing steps to enhance text visibility and separate it from the background. This process typically begins with preprocessing the image to simplify its complexity. Then, edge detection algorithms highlight areas of rapid brightness changes, which often correspond to character boundaries. Morphological operations refine these edges, connecting fragmented segments and reducing noise. Contour detection identifies potential text regions by outlining connected components. To minimize false positives, these contours are filtered based on characteristics like aspect ratio and area. Finally, OCR, using engines like Tesseract, can be applied to the refined regions to recognize and extract the text content. For challenging scenarios with variations in text style and background complexity, advanced techniques like deep learning-based detectors, such as EAST or YOLO, offer more robust solutions.
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) edges = cv2.Canny(gray, 50, 150)kernel = np.ones((5,5),np.uint8)
dilation = cv2.dilate(edges,kernel,iterations = 1)contours, hierarchy = cv2.findContours(dilation, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)for contour in contours:
if cv2.contourArea(contour) > 100 and cv2.contourArea(contour) < 1000:
x,y,w,h = cv2.boundingRect(contour)
cv2.rectangle(image,(x,y),(x+w,y+h),(0,255,0),2)text = pytesseract.image_to_string(cropped_image)net = cv2.dnn.readNet("frozen_east_text_detection.pb")This Python code performs text detection and optical character recognition (OCR) on an image. It uses OpenCV for image processing, pytesseract for OCR, and optionally, the EAST text detector for more advanced detection. The code preprocesses the image, detects edges, finds contours, filters them by area, draws bounding boxes around potential text regions, and performs OCR on these regions. The detected text is then printed. The code also includes a section for using the EAST text detector, which requires downloading the model and implementing additional processing steps.
import cv2
import numpy as np
import pytesseract
# Load the image
image = cv2.imread("image.jpg")
# 1. Preprocessing
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 2. Edge Detection
edges = cv2.Canny(gray, 50, 150)
# 3. Morphological Operations
kernel = np.ones((5, 5), np.uint8)
dilation = cv2.dilate(edges, kernel, iterations=1)
# 4. Contour Detection
contours, hierarchy = cv2.findContours(dilation, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 5. Filtering Contours
for contour in contours:
if cv2.contourArea(contour) > 100 and cv2.contourArea(contour) < 1000:
x, y, w, h = cv2.boundingRect(contour)
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 6. Optical Character Recognition (OCR)
cropped_image = image[y:y+h, x:x+w]
text = pytesseract.image_to_string(cropped_image)
print(f"Detected text: {text}")
# Display the image with detected text regions
cv2.imshow("Text Detection", image)
cv2.waitKey(0)
# 7. Advanced Techniques (Example using EAST text detector)
# Note: This requires downloading the EAST text detector model
# Load the EAST text detector model
net = cv2.dnn.readNet("frozen_east_text_detection.pb")
# Prepare the image for EAST
blob = cv2.dnn.blobFromImage(image, 1.0, (320, 320), (123.68, 116.78, 103.94), swapRB=True, crop=False)
# Perform text detection
net.setInput(blob)
scores, geometry = net.forward(["feature_fusion/Conv_7/Sigmoid", "feature_fusion/concat_3"])
# Process the output and draw bounding boxes around detected text regions
# (Refer to EAST text detector documentation for detailed implementation)
# Display the image with detected text regions
cv2.imshow("Text Detection (EAST)", image)
cv2.waitKey(0)Explanation:
cv2.imread().cv2.cvtColor().cv2.Canny() to find edges in the image.cv2.dilate() to connect broken edges and make text regions more solid.cv2.findContours().cv2.contourArea(). Draw bounding boxes around potential text regions using cv2.rectangle().pytesseract.image_to_string(). Print the detected text.Note:
100 and 1000) based on the size of text in your image.General:
Specific to code:
pytesseract or the EAST model is not found, the code will throw an error. Implementing checks and providing informative messages would make the code more robust.cv2.destroyAllWindows() after displaying the image would ensure proper resource release.Advanced Techniques:
Applications:
This summary outlines a common approach to detecting text within images using computer vision techniques:
1. Preparation:
cv2.cvtColor).2. Identifying Potential Text Regions:
cv2.Canny) to highlight areas with sharp changes in brightness, often indicating character boundaries.cv2.dilate) to connect broken edges and solidify potential text regions.cv2.findContours), which are outlines of connected components, representing potential text areas.3. Refining Results:
4. Text Recognition (Optional):
pytesseract) on the filtered contour regions.5. Advanced Approaches:
This process provides a foundation for text detection in images, with the option to incorporate OCR for text recognition. Advanced techniques like deep learning can further enhance accuracy and handle challenging image conditions.
Extracting text from images, known as Optical Character Recognition (OCR), often involves a series of image processing steps to enhance text visibility and separate it from the background. This process typically begins with preprocessing the image to simplify its complexity. Then, edge detection algorithms highlight areas of rapid brightness changes, which often correspond to character boundaries. Morphological operations refine these edges, connecting fragmented segments and reducing noise. Contour detection identifies potential text regions by outlining connected components. To minimize false positives, these contours are filtered based on characteristics like aspect ratio and area. Finally, OCR, using engines like Tesseract, can be applied to the refined regions to recognize and extract the text content. For challenging scenarios with variations in text style and background complexity, advanced techniques like deep learning-based detectors, such as EAST or YOLO, offer more robust solutions.
 Everything You Need to Know About Social Media Algorithms ... | Social media algorithms have resulted in a big drop in organic reach, but it doesn't mean game over. Use these tips to rise above social media algorithms.
Everything You Need to Know About Social Media Algorithms ... | Social media algorithms have resulted in a big drop in organic reach, but it doesn't mean game over. Use these tips to rise above social media algorithms. Any good algorithms for text localization in images? - Stack Overflow | Aug 30, 2012 ... These may give you some pointers: Algorithm to detect presence of text on image ...
Any good algorithms for text localization in images? - Stack Overflow | Aug 30, 2012 ... These may give you some pointers: Algorithm to detect presence of text on image ...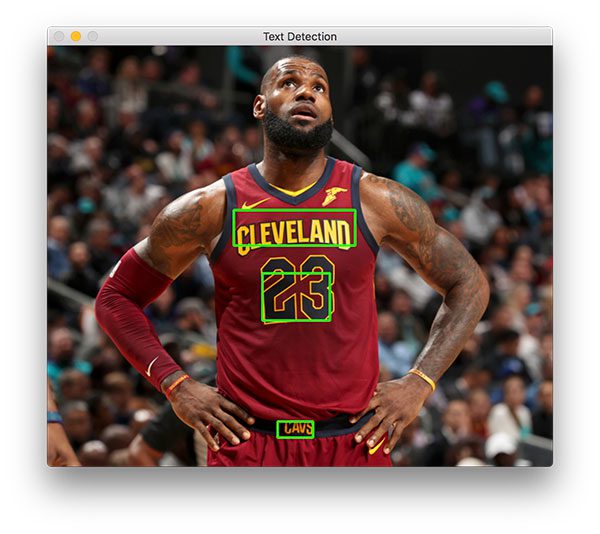 OpenCV Text Detection (EAST text detector) - PyImageSearch | In this tutorial you will learn how to use OpenCV to detect text in images and video, including using OpenCV's EAST text detector for natural scene text detection. c# - What are good algorithms for vehicle license plate detection ... | Jan 16, 2011 ... ... text detection in images as it is related to what you're doing. This question is related to yours: Algorithm to detect presence of text on image.
OpenCV Text Detection (EAST text detector) - PyImageSearch | In this tutorial you will learn how to use OpenCV to detect text in images and video, including using OpenCV's EAST text detector for natural scene text detection. c# - What are good algorithms for vehicle license plate detection ... | Jan 16, 2011 ... ... text detection in images as it is related to what you're doing. This question is related to yours: Algorithm to detect presence of text on image. Azure AI Vision with OCR and AI | Microsoft Azure | Accelerate computer vision development with Microsoft Azure. Get insights from image and video content using OCR, object detection, and image analysis.
Azure AI Vision with OCR and AI | Microsoft Azure | Accelerate computer vision development with Microsoft Azure. Get insights from image and video content using OCR, object detection, and image analysis. Tesseract OCR: Text localization and detection - PyImageSearch | In this tutorial, you will learn how to utilize Tesseract to detect, localize, and OCR text, all within a single, efficient function call.
Tesseract OCR: Text localization and detection - PyImageSearch | In this tutorial, you will learn how to utilize Tesseract to detect, localize, and OCR text, all within a single, efficient function call. What is Azure AI Vision? - Azure AI services | Microsoft Learn | The Azure AI Vision service provides you with access to advanced algorithms for processing images and returning information.
What is Azure AI Vision? - Azure AI services | Microsoft Learn | The Azure AI Vision service provides you with access to advanced algorithms for processing images and returning information. Performance analysis of a deep-learning algorithm to detect the ... | Oct 1, 2024 ... Here, a previously trained deep-learning algorithm enabled acceptable detection of the presence ... Image acquisition and assessment. MRI ...
Performance analysis of a deep-learning algorithm to detect the ... | Oct 1, 2024 ... Here, a previously trained deep-learning algorithm enabled acceptable detection of the presence ... Image acquisition and assessment. MRI ...![YOLO Algorithm for Object Detection Explained [+Examples]](https://framerusercontent.com/images/wmnihLAMWTEv1yW0v6w4ETUz3BQ.jpeg) YOLO Algorithm for Object Detection Explained [+Examples] | What is YOLO architecture and how does it work? Learn about different YOLO algorithm versions and start training your own YOLO object detection models.
YOLO Algorithm for Object Detection Explained [+Examples] | What is YOLO architecture and how does it work? Learn about different YOLO algorithm versions and start training your own YOLO object detection models.