In machine learning, it can be puzzling to encounter a scenario where your model achieves higher accuracy on the validation set than on the training set. This phenomenon, while potentially counterintuitive, can often be attributed to specific factors within your model's training process and data handling. Let's delve into the reasons behind this observation and explore the implications it holds for your model's performance evaluation.
Let's break down why you might see higher accuracy on your validation set compared to your training set in machine learning.
1. Dropout Regularization:
- During training, dropout randomly "turns off" a fraction of your model's neurons.
layer = tf.keras.layers.Dropout(0.2) # 20% dropout
- During validation/testing, dropout is inactive – all neurons are used. This often leads to a more robust and slightly better-performing model on unseen data.
2. Data Splits and Luck:
- Sometimes, your validation set might just be a bit "easier" by random chance due to how you split your data. This is less likely with larger datasets.
3. Underfitting (Rare Case):
- If your validation accuracy is significantly higher than training accuracy, it might indicate underfitting. This means your model is too simple and hasn't learned enough from the training data.
What to Do
-
Don't Panic (Usually): A slightly higher validation accuracy is often a good sign that dropout is working as intended.
-
Check for Overfitting: If the difference is large, investigate overfitting. Techniques include:
- More data
- Simpler model
- Regularization (e.g., more dropout, L1/L2 regularization)
-
Ensure Proper Data Splitting: Use techniques like stratified sampling to create representative training and validation sets.
Key Takeaway: Focus on the performance on your test set (completely unseen data) as the true measure of your model's generalization ability.
This Python code uses TensorFlow and Keras to build and train a simple neural network for image classification on the MNIST dataset. It preprocesses the data, creates a model with a dropout layer for regularization, trains the model, evaluates its performance on a test set, and visualizes the training process. The code demonstrates a basic example of applying dropout for improving model generalization.
import tensorflow as tf
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
# Load your dataset (replace with your own data)
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
# Preprocess data (flatten and normalize)
X_train = X_train.reshape(60000, 784).astype('float32') / 255
X_test = X_test.reshape(10000, 784).astype('float32') / 255
# Create a validation set
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train, test_size=0.2, random_state=42
)
# Build a simple model with dropout
model = Sequential([
Dense(512, activation='relu', input_shape=(784,)),
Dropout(0.5), # 50% dropout
Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Train the model
history = model.fit(X_train, y_train,
epochs=10,
batch_size=128,
validation_data=(X_val, y_val))
# Evaluate on test set
test_loss, test_acc = model.evaluate(X_test, y_test)
print('Test accuracy:', test_acc)
# Plot training and validation accuracy
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()Explanation:
-
Dataset: We use the MNIST dataset for this example.
-
Data Splitting: We split the data into training, validation, and test sets.
-
Dropout: We add a
Dropout layer with a rate of 0.5 (50%) after the first dense layer.
-
Training: We train the model and monitor both training and validation accuracy.
-
Evaluation: We evaluate the final model on the held-out test set.
-
Visualization: We plot the training and validation accuracy curves to visualize the training process.
Observations:
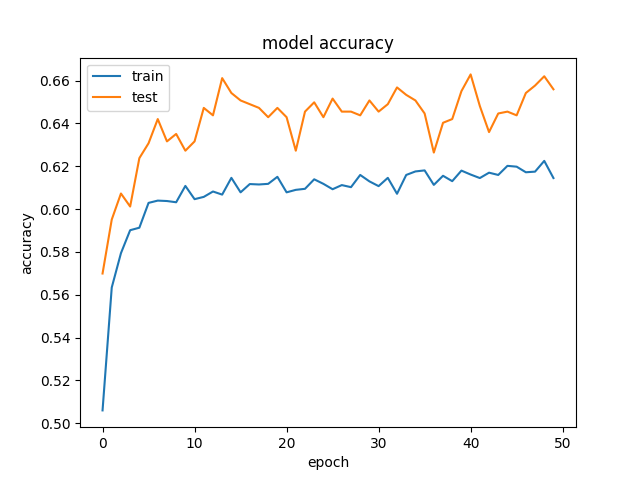
- You'll likely observe that the validation accuracy is slightly higher than the training accuracy during training. This is due to dropout acting as a regularization technique, making the model generalize better to unseen data.
- The difference in accuracy should be relatively small. If it's very large, it might indicate underfitting or issues with your data split.
Remember: The test set accuracy is the most reliable indicator of your model's performance on new, unseen data.
Dropout Regularization:
- The optimal dropout rate (e.g., 0.2, 0.5) is problem-specific. You can tune it using techniques like cross-validation.
- Dropout is most effective in layers with a large number of neurons.
- Visualize the training and validation curves (as shown in the code example) to see the impact of dropout on overfitting.
Data Splits and Luck:
- The smaller your dataset, the more likely you are to see fluctuations in accuracy due to random splits.
- Consider using k-fold cross-validation to get a more robust estimate of your model's performance, especially with limited data.
Underfitting (Rare Case):
-
Signs of underfitting: Both training and validation accuracy are low, and the model fails to capture the underlying patterns in the data.
-
Addressing underfitting: Increase model complexity (add layers, neurons), use a more powerful architecture, or train for more epochs.
Other Factors:
-
Batch size: Smaller batch sizes can sometimes lead to slightly higher validation accuracy due to the added noise in the training process.
-
Early stopping: This technique stops training when the validation accuracy plateaus, preventing the model from overfitting to the training data.
Important Considerations:
-
Focus on generalization: The ultimate goal is to build a model that performs well on unseen data. Don't over-optimize for a slightly higher validation accuracy at the expense of test set performance.
-
Reproducibility: Use fixed random seeds for data splitting and model initialization to ensure consistent results across different runs.
-
Experimentation: Machine learning is empirical. Don't be afraid to experiment with different architectures, hyperparameters, and regularization techniques to find what works best for your specific problem.
| Reason | Explanation
Higher validation set accuracy compared to the training set accuracy, while sometimes unexpected, can often be attributed to regularization techniques like dropout, random data split variations, or in rarer cases, underfitting. Dropout, active during training but inactive during validation, often leads to more robust models that perform slightly better on unseen data. Random data splits, especially with smaller datasets, can lead to an easier validation set purely by chance. However, significantly higher validation accuracy might indicate underfitting, where the model is too simple to learn effectively from the training data. It's crucial to remember that the test set accuracy, derived from completely unseen data, is the most reliable measure of your model's generalization ability. Therefore, while a slightly higher validation accuracy is generally a positive sign, substantial differences warrant investigation for potential overfitting or underfitting. Focus on achieving a balance between training and validation performance, and prioritize the model's performance on the unseen test set for a realistic evaluation of its real-world applicability.