Tensorflow
TensorFlow 2 vs 1: Why the Performance Drop?
Discover the reasons behind TensorFlow 2's performance differences compared to TensorFlow 1 and learn how to optimize your deep learning models.
Discover the reasons behind TensorFlow 2's performance differences compared to TensorFlow 1 and learn how to optimize your deep learning models.

TensorFlow 2, while generally praised for its user-friendly eager execution mode, can sometimes exhibit slower performance compared to its predecessor, TensorFlow 1. This performance difference might be particularly noticeable in certain scenarios or specific configurations. This article delves into potential reasons behind TensorFlow 2's performance bottlenecks and provides practical solutions to mitigate them.
TensorFlow 2, while offering advantages like eager execution, can sometimes be slower than TensorFlow 1, especially in specific scenarios or configurations. Here's a breakdown of potential reasons and solutions:
1. Eager Execution Overhead:
tf.function to compile graphs for optimized execution.@tf.function
def my_function(x):
# Your code here
return x2. Hardware and Software Configuration:
3. Data Input Pipelines:
tf.data.Dataset for optimized data pipelines.dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
dataset = dataset.batch(batch_size)4. Model Architecture and Complexity:
5. Debugging and Profiling:
6. Framework Comparison (TensorFlow vs. PyTorch):
7. Containerization (Docker):
8. Operating System and Environment:
9. Code Optimization:
10. TensorFlow Version Updates:
Remember that performance is context-dependent. Thoroughly analyze your specific scenario, profile your code, and experiment with different configurations to identify and address performance bottlenecks.
This Python code demonstrates various techniques to optimize TensorFlow 2 performance. It showcases the use of tf.function for graph optimization, tf.data.Dataset for efficient data input pipelines, and TensorFlow Profiler for identifying bottlenecks. The code also highlights the importance of vectorized operations and provides examples of inefficient and efficient code implementations. Additionally, it mentions other optimization strategies such as hardware and software configuration, model architecture optimization, framework comparison, containerization, operating system optimization, and TensorFlow version updates.
import tensorflow as tf
import time
# --- 1. Eager Execution Overhead ---
# Example of slow eager execution in a loop
def slow_function(x, iterations=1000):
for _ in range(iterations):
x = x * 2
return x
# Solution: Use tf.function for graph optimization
@tf.function
def fast_function(x, iterations=1000):
for _ in range(iterations):
x = x * 2
return x
# --- 3. Data Input Pipelines ---
# Example of inefficient data loading
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# Solution: Use tf.data.Dataset for optimized pipelines
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
dataset = dataset.batch(32)
# --- 5. Debugging and Profiling ---
# Example of using TensorFlow Profiler (requires installation)
# tf.profiler.experimental.start('logdir')
# # Run your TensorFlow code here
# tf.profiler.experimental.stop()
# --- 9. Code Optimization ---
# Example of inefficient code
def inefficient_sum(x, y):
for i in range(len(x)):
x[i] += y[i]
return x
# Solution: Use vectorized operations
def efficient_sum(x, y):
return x + y
# --- Performance Comparison ---
x = tf.random.normal((1000,))
start_time = time.time()
slow_result = slow_function(x)
print("Slow Function Time:", time.time() - start_time)
start_time = time.time()
fast_result = fast_function(x)
print("Fast Function Time:", time.time() - start_time)
# --- Other Solutions ---
# 2. Hardware and Software Configuration: Ensure compatible CUDA/cuDNN
# 4. Model Architecture and Complexity: Simplify or optimize model
# 6. Framework Comparison: Consider PyTorch for specific use cases
# 7. Containerization (Docker): Configure resources and hardware access
# 8. Operating System and Environment: Resolve OS or library issues
# 10. TensorFlow Version Updates: Upgrade to the latest stable versionExplanation:
slow_function) and compiling a graph with tf.function (fast_function).tf.data.Dataset for efficient data loading and batching.inefficient_sum) with a vectorized operation (efficient_sum) for improved performance.Note:
General Considerations:
Specific to Solutions:
tf.function:
input_signature specifications in tf.function to potentially improve performance for varying input shapes.tf.function as they can hinder performance.dataset.prefetch(tf.data.AUTOTUNE)) to overlap data loading and model training for improved efficiency.dataset.cache()) if your dataset fits in memory to avoid redundant data loading.Beyond the Article:
Remember: Performance optimization is an iterative process. Continuously profile, analyze, and experiment to find the optimal configuration for your specific TensorFlow 2 application.
While TensorFlow 2 offers advantages like eager execution, it can sometimes be slower than TensorFlow 1. Here's a summary of potential reasons and solutions:
| Issue Category | Potential Reason | Solution |
|---|---|---|
| Execution Mode | Eager execution overhead for small operations, especially in loops. | Use tf.function to compile graphs for optimized execution. |
| Configuration | Incorrect CUDA/cuDNN versions or settings. | Ensure compatible and optimized versions are installed and configured correctly. |
| Data Handling | Inefficient data loading and preprocessing. | Utilize tf.data.Dataset for optimized data pipelines. |
| Model Design | Complex models with numerous layers or operations. | Consider model simplification or optimization techniques. |
| Debugging & Profiling | Lack of performance analysis. | Use TensorFlow Profiler to identify and optimize bottlenecks. |
| Framework Choice | PyTorch's dynamic graph might be faster for certain operations. | Choose the framework that best suits your needs and performance requirements. |
| Containerization | Incorrect Docker configuration (e.g., limited CPU/GPU access). | Configure Docker resources appropriately and ensure proper hardware access. |
| System Environment | OS-level configurations or library conflicts. | Investigate and resolve any OS-related issues or library incompatibilities. |
| Code Quality | Inefficient code or algorithms. | Review and optimize your code for better performance. |
| TensorFlow Version | Older versions may lack performance improvements. | Consider upgrading to the latest stable version. |
Key Takeaway: Performance is context-dependent. Analyze your specific scenario, profile your code, and experiment with different configurations to identify and address performance bottlenecks.
In conclusion, while TensorFlow 2 introduces new conveniences like eager execution, its performance can sometimes lag behind TensorFlow 1. Factors such as eager execution overhead, configuration issues, inefficient data pipelines, and complex model architectures can contribute to slower execution. However, by leveraging solutions like tf.function, optimized data pipelines with tf.data.Dataset, and tools like TensorFlow Profiler, developers can mitigate these bottlenecks. Choosing the right framework based on project needs, ensuring proper hardware and software configurations, and writing efficient code are crucial for optimal performance. Ultimately, a comprehensive understanding of the potential performance pitfalls and the available solutions empowers developers to harness the full potential of TensorFlow 2 for their machine learning tasks.
 Jetson Xavier NX - Tensorflow 2 container slower on GPU than on ... | Hi everyone, this week I received my Jetson Xavier NX developer board and started playing a bit with it. I found-out that NVidia provides a Docker image based on L4T with Tensorflow 1 installed. I used it’s Dockerfile and created a similar container with Tensorflow 2. The new Dockerfile is here and the image on Dockerhub with tag carlosedp/l4t-tensorflow:r32.4.2-tf1-py3. While testing it with Tensorflow “hello world” sample below from Tensorflow site, I found out two things: The time to run ...
Jetson Xavier NX - Tensorflow 2 container slower on GPU than on ... | Hi everyone, this week I received my Jetson Xavier NX developer board and started playing a bit with it. I found-out that NVidia provides a Docker image based on L4T with Tensorflow 1 installed. I used it’s Dockerfile and created a similar container with Tensorflow 2. The new Dockerfile is here and the image on Dockerhub with tag carlosedp/l4t-tensorflow:r32.4.2-tf1-py3. While testing it with Tensorflow “hello world” sample below from Tensorflow site, I found out two things: The time to run ... Tensorflow slower as NixOS native than inside a Docker container ... | Hey all! I’m trying to make our data science infrastructue more pure. We have a Tensorflow project that does some computation. At the moment, the computation is done inside a Docker container. I’d like to do the computation natively on NixOS, so I can get rid of Docker. The problem is that the computation is about 10% slower natively than it is inside the Docker container. I can’t figure out why and am looking for ideas what else to try. I’m doing the testing on a single g4dn.xlarge AWS instance...
Tensorflow slower as NixOS native than inside a Docker container ... | Hey all! I’m trying to make our data science infrastructue more pure. We have a Tensorflow project that does some computation. At the moment, the computation is done inside a Docker container. I’d like to do the computation natively on NixOS, so I can get rid of Docker. The problem is that the computation is about 10% slower natively than it is inside the Docker container. I can’t figure out why and am looking for ideas what else to try. I’m doing the testing on a single g4dn.xlarge AWS instance... PyTorch slower than Tensorflow/Keras during training - PyTorch ... | Hi, I’m porting a Tensorflow project to PyTorch and after executing I realize that Tensorflow is faster than PyTorch during training and it’s weird to me. I isolate the 2 projects in 2 different notebooks with all classes and functions needed to train the model. Remember this is just a snippet of a bigger project (a project that uses genetic algorithms) and that’s why CustomModel/TFModelConvert module needs to receive a list of arbitrary Resblock modules. In the TensorFlow notebook, you will...
PyTorch slower than Tensorflow/Keras during training - PyTorch ... | Hi, I’m porting a Tensorflow project to PyTorch and after executing I realize that Tensorflow is faster than PyTorch during training and it’s weird to me. I isolate the 2 projects in 2 different notebooks with all classes and functions needed to train the model. Remember this is just a snippet of a bigger project (a project that uses genetic algorithms) and that’s why CustomModel/TFModelConvert module needs to receive a list of arbitrary Resblock modules. In the TensorFlow notebook, you will... Why Tensorflow Models are way slower than Pytorch models, for ... | Hi, I was experimenting with many models include GPT2, T5 etc. But it seems like Tensorflow models are too slow for same type of generation comparing to Tensorflow, whether it is greedy, beam etc . Any specific reasons for this? Thanks
Why Tensorflow Models are way slower than Pytorch models, for ... | Hi, I was experimenting with many models include GPT2, T5 etc. But it seems like Tensorflow models are too slow for same type of generation comparing to Tensorflow, whether it is greedy, beam etc . Any specific reasons for this? Thanks Swift 4 TensorFlow is 10x slower when running in xcode versus ... | Hi Everyone, Please excuse me and redirect me to the appropriate forum to ask this question if necessary. My question concerns the swift-4-tensorflow framework. I recently started reading David Foster's "Generative Deep Learning" book. I want to follow the examples, but I prefer swift over Python, and additionaly I prefer running my code in xcode instead of jupyter notebook. I successfully converted his first notebook example python code to Swift using the "TensorFlow" swift library and I ca...
Swift 4 TensorFlow is 10x slower when running in xcode versus ... | Hi Everyone, Please excuse me and redirect me to the appropriate forum to ask this question if necessary. My question concerns the swift-4-tensorflow framework. I recently started reading David Foster's "Generative Deep Learning" book. I want to follow the examples, but I prefer swift over Python, and additionaly I prefer running my code in xcode instead of jupyter notebook. I successfully converted his first notebook example python code to Swift using the "TensorFlow" swift library and I ca...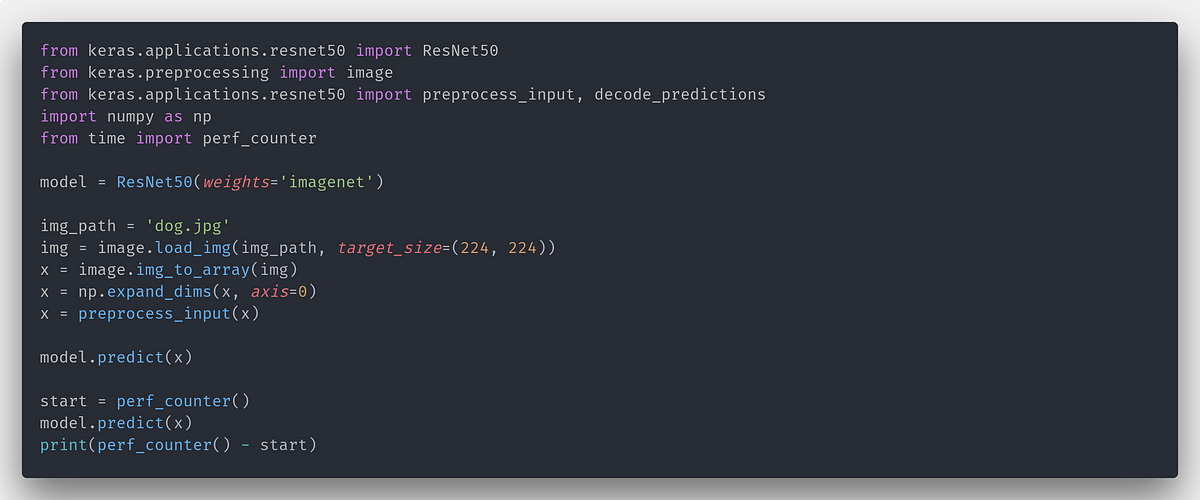 How a badly configured Tensorflow in Docker can be 10x slower ... | Follow me on Twitter for more AI / Cloud / Tech related stuff!
How a badly configured Tensorflow in Docker can be 10x slower ... | Follow me on Twitter for more AI / Cloud / Tech related stuff!