Tensorflow
TensorFlow Regularization: L1, L2 & Dropout Tutorial
Learn how to prevent overfitting in your TensorFlow models by implementing L1, L2, and dropout regularization techniques.
Learn how to prevent overfitting in your TensorFlow models by implementing L1, L2, and dropout regularization techniques.

Regularization techniques are essential for preventing overfitting in neural networks, thereby improving their ability to generalize well to unseen data. This article provides a concise guide on implementing different regularization methods in TensorFlow/Keras, a popular deep learning framework. We will cover L1, L2, and dropout regularization, illustrating how to incorporate them into your neural network models.
Import necessary libraries:
from tensorflow.keras import layers, regularizersDefine the regularization strength:
l2_strength = 0.01 # Adjust this value as neededAdd L2 regularization to a layer:
model.add(layers.Dense(64,
kernel_regularizer=regularizers.l2(l2_strength),
activation='relu'))Alternatively, use L1 regularization:
model.add(layers.Dense(64,
kernel_regularizer=regularizers.l1(l2_strength),
activation='relu'))For dropout regularization, add a Dropout layer:
model.add(layers.Dropout(0.5)) # 0.5 dropout rateCompile and train your model as usual. The regularization penalty will be added to the loss function during training.
This Python code defines a simple sequential neural network using TensorFlow and Keras. It demonstrates how to apply L1, L2, and dropout regularization techniques to the model's layers to prevent overfitting. The code includes adding dense layers with ReLU activation, a dropout layer, and an output layer with softmax activation. It also shows how to compile the model with an optimizer, loss function, and metrics, although the actual training process is commented out. The code provides a basic example of building and regularizing a neural network for classification tasks.
import tensorflow as tf
from tensorflow.keras import layers, regularizers
# Define the regularization strength
l2_strength = 0.01
# Create a simple model
model = tf.keras.Sequential()
# Add a Dense layer with L2 regularization
model.add(layers.Dense(64,
kernel_regularizer=regularizers.l2(l2_strength),
activation='relu',
input_shape=(10,))) # Assuming input shape (10,)
# Add another Dense layer with L1 regularization
model.add(layers.Dense(32,
kernel_regularizer=regularizers.l1(l2_strength),
activation='relu'))
# Add a Dropout layer for dropout regularization
model.add(layers.Dropout(0.5))
# Add the output layer
model.add(layers.Dense(10, activation='softmax'))
# Compile the model
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Print the model summary to see the regularization applied
model.summary()
# Prepare your data (replace with your own dataset)
# ...
# Train the model
# model.fit(x_train, y_train, epochs=10, validation_data=(x_val, y_val))Explanation:
kernel_regularizer argument specifies the regularization technique to use.Key points:
General:
l2_strength) and dropout rate are hyperparameters that need to be tuned to find the optimal values for your specific dataset and model architecture. Techniques like cross-validation can be used for this purpose.L1 and L2 Regularization:
Dropout Regularization:
Code Example Enhancements:
Beyond the Basics:
This code snippet demonstrates how to implement different regularization techniques in TensorFlow/Keras to prevent overfitting in neural networks:
1. L2 Regularization:
l2_strength) to the loss function. This encourages the model to learn smaller, more generalized weights.kernel_regularizer=regularizers.l2(l2_strength) within a layer definition.2. L1 Regularization:
kernel_regularizer=regularizers.l1(l2_strength) within a layer definition.3. Dropout Regularization:
layers.Dropout(rate) layer after the layer you want to apply dropout to. rate represents the dropout rate (e.g., 0.5 for dropping 50% of neurons).General Notes:
l2_strength) controls the impact of the regularization penalty. Higher values lead to stronger regularization.By applying these techniques and carefully tuning their parameters, you can enhance the generalization ability of your models, making them more robust and reliable for real-world applications. Remember that the choice of regularization techniques and their strength often depends on the specific dataset and model architecture, so experimentation and validation are crucial for finding the optimal settings. This article provides a foundational understanding of regularization in TensorFlow/Keras, empowering you to build more robust and generalizable neural networks.
 tf.keras.Regularizer | TensorFlow v2.16.1 | Regularizer base class. tf.keras.regularizers.L2 | TensorFlow v2.16.1 | A regularizer that applies a L2 regularization penalty.
tf.keras.Regularizer | TensorFlow v2.16.1 | Regularizer base class. tf.keras.regularizers.L2 | TensorFlow v2.16.1 | A regularizer that applies a L2 regularization penalty. Applying L2 Regularization to All Weights in TensorFlow ... | A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
Applying L2 Regularization to All Weights in TensorFlow ... | A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.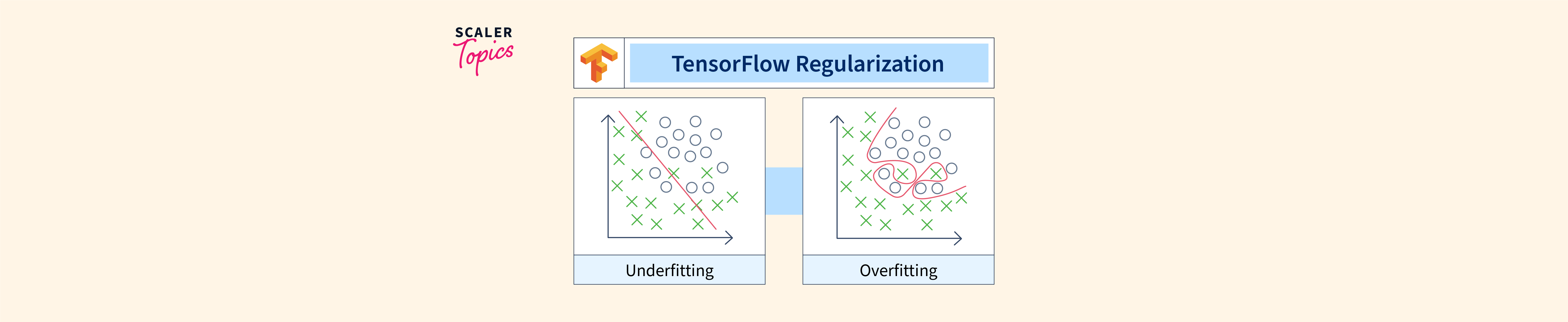 TensorFlow Regularization - Scaler Topics | This tutorial covers the concept of regularization in machine learning and how to implement L1 and L2 regularization using TensorFlow. Learn how to improve your models by preventing overfitting and tuning regularization strength.
TensorFlow Regularization - Scaler Topics | This tutorial covers the concept of regularization in machine learning and how to implement L1 and L2 regularization using TensorFlow. Learn how to improve your models by preventing overfitting and tuning regularization strength. Convolutional Neural Network and Regularization Techniques with ... | This GIF shows how neural network “learns” from its input. We don’t want the neural network pick up unwanted patterns nor do we want the…
Convolutional Neural Network and Regularization Techniques with ... | This GIF shows how neural network “learns” from its input. We don’t want the neural network pick up unwanted patterns nor do we want the…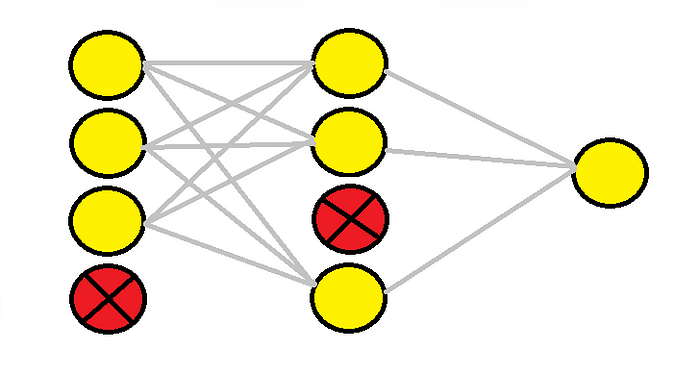 Dropout Regularization With Tensorflow Keras - Comet | Deep neural networks are complex models which makes them much more prone to overfitting — especially when the dataset has few examples. Left unhandled, an overfit model would fail to generalize well to unseen instances.
Dropout Regularization With Tensorflow Keras - Comet | Deep neural networks are complex models which makes them much more prone to overfitting — especially when the dataset has few examples. Left unhandled, an overfit model would fail to generalize well to unseen instances. How to Add Regularization to Keras Pre-trained Models the Right ... | Nov 26, 2019 ... How to Add Regularization to Keras Pre-trained Models the Right Way. [ machine-learning deep-learning regularization tensorflow keras ].
How to Add Regularization to Keras Pre-trained Models the Right ... | Nov 26, 2019 ... How to Add Regularization to Keras Pre-trained Models the Right Way. [ machine-learning deep-learning regularization tensorflow keras ].