Tensorflow
sparse_categorical_crossentropy vs categorical_crossentropy: Key Differences
This article explains the difference between sparse_categorical_crossentropy and categorical_crossentropy loss functions in machine learning.
This article explains the difference between sparse_categorical_crossentropy and categorical_crossentropy loss functions in machine learning.

In the realm of multi-class classification using deep learning, choosing the appropriate loss function is crucial for effective model training. Two commonly encountered options are categorical_crossentropy and sparse_categorical_crossentropy. While both serve the purpose of measuring the dissimilarity between predicted and true labels, they differ in the format of target labels they expect. This distinction influences their suitability for different scenarios.
Both categorical_crossentropy and sparse_categorical_crossentropy are loss functions used for multi-class classification in deep learning. The key difference lies in the format of your target labels (y_true).
categorical_crossentropy
y_true = [0, 1, 0] sparse_categorical_crossentropy
y_true = 2 When to use which?
sparse_categorical_crossentropy is generally preferred when:
categorical_crossentropy is used when:
In essence: sparse_categorical_crossentropy simplifies your workflow by handling the integer-to-one-hot encoding internally, while categorical_crossentropy requires you to provide one-hot encoded labels directly.
The Python code demonstrates the calculation of categorical cross-entropy loss using TensorFlow. It showcases two methods: sparse_categorical_crossentropy for integer labels and categorical_crossentropy for one-hot encoded labels. The code generates random predictions and compares the loss values obtained from both methods, highlighting their equivalence when used with appropriate label formats.
import tensorflow as tf
# Sample data
num_classes = 3
num_samples = 5
# Generate random predictions (probabilities for each class)
predictions = tf.random.uniform(shape=(num_samples, num_classes))
# --- Example 1: sparse_categorical_crossentropy ---
y_true_sparse = [1, 0, 2, 1, 2] # Integer labels
loss_sparse = tf.keras.losses.sparse_categorical_crossentropy(
y_true=y_true_sparse, y_pred=predictions
)
print("Sparse Categorical Crossentropy Loss:", loss_sparse.numpy())
# --- Example 2: categorical_crossentropy ---
y_true_onehot = tf.keras.utils.to_categorical(y_true_sparse, num_classes=num_classes)
loss_categorical = tf.keras.losses.categorical_crossentropy(
y_true=y_true_onehot, y_pred=predictions
)
print("Categorical Crossentropy Loss:", loss_categorical.numpy()) Explanation:
tf.y_true_sparse: Integer labels (0, 1, 2) representing the true class for each sample.y_true_onehot: One-hot encoded version of y_true_sparse.tf.keras.losses.sparse_categorical_crossentropy with y_true_sparse (integer labels).tf.keras.losses.categorical_crossentropy with y_true_onehot (one-hot encoded labels).Key Points:
sparse_categorical_crossentropy is generally more efficient for a large number of classes, as it avoids the overhead of creating and processing large one-hot encoded vectors.sparse_categorical_crossentropy is generally more memory-efficient, especially when dealing with a large number of classes. This is because it avoids storing and computing with large one-hot encoded vectors.sparse_categorical_crossentropy simplifies the input, it internally performs the conversion from integer labels to one-hot encoding before calculating the loss.kullback_leibler_divergence. The choice of the best loss function depends on the specific problem and characteristics of your data.| Feature | categorical_crossentropy |
sparse_categorical_crossentropy |
|---|---|---|
| Target Label Format | One-hot encoded (e.g., [0, 1, 0]) |
Integer (e.g., 2) |
| When to Use | Labels already one-hot encoded, specific reasons for using one-hot encoding | Large number of classes, mutually exclusive labels |
| Advantages | Direct use of one-hot encoded labels | Simplified workflow, internal integer-to-one-hot encoding |
Key Takeaway: Both are loss functions for multi-class classification. Choose sparse_categorical_crossentropy for simpler handling of integer labels, especially with many classes. Use categorical_crossentropy if you're already working with one-hot encoded labels.
In conclusion, understanding the distinction between categorical_crossentropy and sparse_categorical_crossentropy is essential for selecting the appropriate loss function in multi-class classification tasks. While both assess the difference between predicted and actual labels, their application hinges on the format of the target labels. sparse_categorical_crossentropy emerges as a more streamlined choice for scenarios involving a large number of classes or when working with integer-based labels, as it handles the conversion to one-hot encoding internally. Conversely, categorical_crossentropy proves valuable when dealing with pre-existing one-hot encoded labels or when specific circumstances necessitate their use. The provided Python code examples offer practical illustrations of both loss functions using TensorFlow, emphasizing their comparable outcomes when employed with the correct label formats. Ultimately, the choice between these loss functions depends on the specific characteristics of the dataset and the overall workflow of the deep learning model. By grasping the nuances of each function, practitioners can make informed decisions to optimize their model training process and achieve better classification results.
 Sparse_categorical_crossentropy vs categorical_crossentropy ... | Dec 1, 2018 ... Use sparse categorical crossentropy when your classes are mutually exclusive (e.g. when each sample belongs exactly to one class) and ...
Sparse_categorical_crossentropy vs categorical_crossentropy ... | Dec 1, 2018 ... Use sparse categorical crossentropy when your classes are mutually exclusive (e.g. when each sample belongs exactly to one class) and ... Sparse_categorical_crossentropy v.s. categorical_crossentropy on ... | I am working on the assignment of Course2 Week4. I have thought those two (sparse_categorical_crossentropy v.s. categorical_crossentropy) should work but actually categorical_crossentropy causes an error of model.fit; ValueError: Shapes (None, 1) and (None, 26) are incompatible It seems that these 1 and 26 correspond to the number of categories, because model.fit runs when I reduce the number of outputs to 1 on the last layer. So, categorical_crossentropy looks not work with non-binary outp...
Sparse_categorical_crossentropy v.s. categorical_crossentropy on ... | I am working on the assignment of Course2 Week4. I have thought those two (sparse_categorical_crossentropy v.s. categorical_crossentropy) should work but actually categorical_crossentropy causes an error of model.fit; ValueError: Shapes (None, 1) and (None, 26) are incompatible It seems that these 1 and 26 correspond to the number of categories, because model.fit runs when I reduce the number of outputs to 1 on the last layer. So, categorical_crossentropy looks not work with non-binary outp...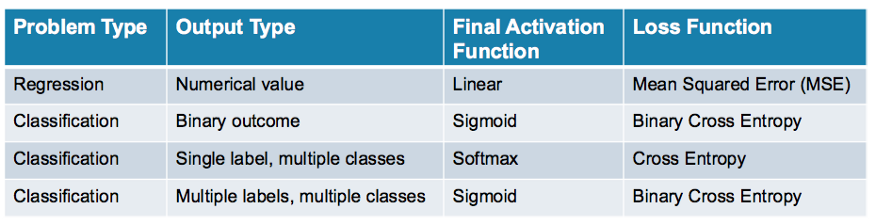 Sparse Categorical Cross-Entropy vs Categorical Cross-Entropy | by ... | Many of you have the following question “In which situations should I use a specific loss function like categorical, sparse, binary, etc?”
Sparse Categorical Cross-Entropy vs Categorical Cross-Entropy | by ... | Many of you have the following question “In which situations should I use a specific loss function like categorical, sparse, binary, etc?” machine learning - Cross Entropy vs. Sparse Cross Entropy: When ... | Jan 31, 2018 ... ... categorical_crossentropy. Examples (for a 3-class ... Have you it there? Difference between たやすい and やさしい · How are ...
machine learning - Cross Entropy vs. Sparse Cross Entropy: When ... | Jan 31, 2018 ... ... categorical_crossentropy. Examples (for a 3-class ... Have you it there? Difference between たやすい and やさしい · How are ... What is the difference between categorical_crossentropy and ... | Jan 2, 2019 ... The main difference is the former one has the output in the form of one hot encoded vectors whereas the latter has it in integers. The sparse ...
What is the difference between categorical_crossentropy and ... | Jan 2, 2019 ... The main difference is the former one has the output in the form of one hot encoded vectors whereas the latter has it in integers. The sparse ... Categorical cross entropy loss function equivalent in PyTorch ... | Hi, I found Categorical cross-entropy loss in Theano and Keras. Is nn.CrossEntropyLoss() equivalent of this loss function? I saw this topic but three is not a solution for that.
Categorical cross entropy loss function equivalent in PyTorch ... | Hi, I found Categorical cross-entropy loss in Theano and Keras. Is nn.CrossEntropyLoss() equivalent of this loss function? I saw this topic but three is not a solution for that.