Machine Vision
Semantic Segmentation vs Segmentation vs Scene Labeling: Key Differences
This article explains semantic segmentation in computer vision and differentiates it from related concepts like segmentation and scene labeling.
This article explains semantic segmentation in computer vision and differentiates it from related concepts like segmentation and scene labeling.

In the realm of computer vision, understanding images goes beyond simply recognizing objects. We can dissect and interpret images with increasing levels of detail using techniques like image segmentation, semantic segmentation, and scene labeling. Each of these approaches offers a unique perspective on image analysis, providing valuable insights for various applications.
Image Segmentation: Dividing an image into multiple segments or regions. Think of it like coloring a picture within the lines, but you don't care what each segment represents.
# Example: Simple thresholding for segmentation
import cv2
img = cv2.imread('image.jpg', 0)
ret, thresh = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)Semantic Segmentation: Taking image segmentation a step further by assigning a meaningful label to each pixel in the image. Now, you're not just coloring within the lines, you're labeling each area as "sky," "tree," "road," etc.
# Example: Using a pre-trained model for semantic segmentation
from model import DeepLabModel
model = DeepLabModel()
segmented_image = model.run(image) Scene Labeling: Similar to semantic segmentation, but the focus is on understanding the overall scene depicted in the image. It's like giving a single label to the entire image, such as "park," "beach," or "city street."
# Example: Classifying an image scene
from tensorflow.keras.applications.resnet50 import ResNet50
model = ResNet50(weights='imagenet')
predictions = model.predict(image)
predicted_class = decode_predictions(predictions, top=1)[0][0][1]Key Differences:
In short:
This Python code demonstrates three image understanding techniques using OpenCV and TensorFlow/Keras. It first performs basic image segmentation by thresholding a grayscale image. Then, it outlines the concept of semantic segmentation using a placeholder for a pre-trained model, where the goal is to classify each pixel into specific categories. Finally, it utilizes a pre-trained ResNet50 model for scene labeling, predicting the overall scene depicted in an input image.
# 1. Image Segmentation: Thresholding
import cv2
# Load the image in grayscale
img = cv2.imread('image.jpg', 0)
# Apply thresholding to segment the image
ret, thresh = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
# Display the segmented image
cv2.imshow('Segmented Image', thresh)
cv2.waitKey(0)
cv2.destroyAllWindows()
# ------------------------------------------------------------------
# 2. Semantic Segmentation: Using a pre-trained model (example)
# Note: This requires a pre-trained model and appropriate libraries.
from model import DeepLabModel # Replace with your actual model import
# Load the pre-trained model
model = DeepLabModel()
# Load the image
image = cv2.imread('image.jpg')
# Perform semantic segmentation
segmented_image = model.run(image)
# Visualize the results (example)
cv2.imshow('Segmented Image', segmented_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# ------------------------------------------------------------------
# 3. Scene Labeling: Using ResNet50 for image classification
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
from tensorflow.keras.preprocessing import image
import numpy as np
# Load the pre-trained ResNet50 model
model = ResNet50(weights='imagenet')
# Load and preprocess the image
img_path = 'image.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
# Make predictions
predictions = model.predict(x)
# Decode the predictions to get human-readable labels
predicted_class = decode_predictions(predictions, top=1)[0][0][1]
# Print the predicted scene label
print("Predicted Scene:", predicted_class)Explanation:
Image Segmentation (Thresholding):
cv2.threshold() applies a threshold to separate pixels into two groups: those below the threshold (127 in this case) become black (0), and those above become white (255). This creates a simple segmented image.Semantic Segmentation (Conceptual):
from model import DeepLabModel and the subsequent code with the actual import and usage of your chosen pre-trained semantic segmentation model (e.g., DeepLab, U-Net, etc.).Scene Labeling (ResNet50):
model.predict() gives us the probabilities for different ImageNet classes.decode_predictions() converts these probabilities into human-readable labels.Remember:
Image Segmentation:
Semantic Segmentation:
Scene Labeling:
General Notes:
| Task | Description
From basic segmentation to advanced scene labeling, these techniques offer a powerful toolkit for machines to perceive and interpret the visual world. As research progresses, we can expect even more sophisticated methods, pushing the boundaries of computer vision and enabling applications that were once considered science fiction.
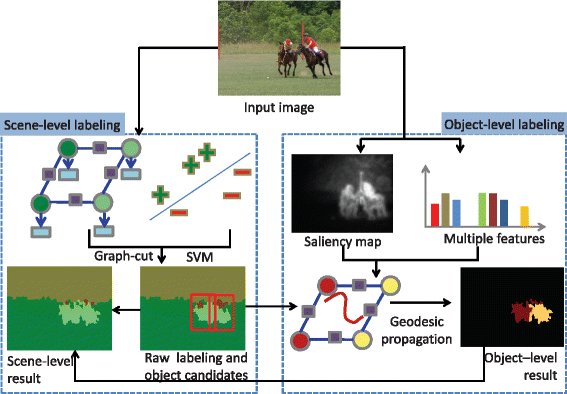 Hierarchical semantic segmentation of image scene with object ... | Mar 1, 2018 ... Semantic segmentation of an image scene provides semantic ... RGB-(D) scene labeling: Features and algorithms (IEEE Computer ...
Hierarchical semantic segmentation of image scene with object ... | Mar 1, 2018 ... Semantic segmentation of an image scene provides semantic ... RGB-(D) scene labeling: Features and algorithms (IEEE Computer ... computer vision - Semantic Segmentation or Object Detection ... | Sep 6, 2022 ... Why is image segmentation needed for object detection? 105 · What is "semantic segmentation" compared to "segmentation" and "scene labeling"? 2.
computer vision - Semantic Segmentation or Object Detection ... | Sep 6, 2022 ... Why is image segmentation needed for object detection? 105 · What is "semantic segmentation" compared to "segmentation" and "scene labeling"? 2. Image semantic segmentation of indoor scenes: A survey ... | This survey provides a comprehensive evaluation of various deep learning-based segmentation architectures. It covers a wide range of models, from trad…
Image semantic segmentation of indoor scenes: A survey ... | This survey provides a comprehensive evaluation of various deep learning-based segmentation architectures. It covers a wide range of models, from trad… Semantic segmentation of 3D textured meshes for urban scene ... | Classifying 3D measurement data has become a core problem in photogrammetry and 3D computer vision, since the rise of modern multiview geometry techni…
Semantic segmentation of 3D textured meshes for urban scene ... | Classifying 3D measurement data has become a core problem in photogrammetry and 3D computer vision, since the rise of modern multiview geometry techni… SnapNet: 3D point cloud semantic labeling with 2D deep ... | In this work, we describe a new, general, and efficient method for unstructured point cloud labeling. As the question of efficiently using deep Convol…
SnapNet: 3D point cloud semantic labeling with 2D deep ... | In this work, we describe a new, general, and efficient method for unstructured point cloud labeling. As the question of efficiently using deep Convol… Deep Learning in Object Recognition, Detection, and Segmentation | Jul 14, 2016 ... On the segmentation side, the article discusses the most recent progress on scene labeling, semantic segmentation, face parsing, human parsing ...
Deep Learning in Object Recognition, Detection, and Segmentation | Jul 14, 2016 ... On the segmentation side, the article discusses the most recent progress on scene labeling, semantic segmentation, face parsing, human parsing ...