Tensorflow
Deep Learning Nan Loss: Troubleshooting & Solutions
This article explores the common causes and solutions for encountering "NaN loss" during deep learning model training.
This article explores the common causes and solutions for encountering "NaN loss" during deep learning model training.

Encountering NaN (Not a Number) loss during deep learning training can be a significant roadblock. This issue arises when your model's calculations produce undefined numerical values, effectively halting the learning process. This article will guide you through the common culprits behind NaN loss and provide practical solutions to get your training back on track. We'll cover issues ranging from exploding gradients and learning rate problems to potential data preprocessing errors and numerical instabilities within your model.
Encountering NaN (Not a Number) loss during deep learning training can be frustrating. Here's a breakdown of common causes and how to address them:
1. Exploding Gradients & Learning Rate:
NaN values.optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) # Try 1e-4 or smaller2. Loss Function Issues:
log(0)) with specific inputs.3. Input Data Problems:
NaN values in your training data can propagate through calculations.NaN values in your dataset.4. Stride and Kernel Size Mismatch:
5. Other Potential Causes:
NaN.Debugging Tips:
NaN values first appear.torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)Remember, debugging NaN loss often involves a combination of careful code inspection, data analysis, and experimentation with hyperparameters.
The Python code defines a simple neural network model using PyTorch and implements strategies to address exploding gradients during training. It includes setting a low learning rate, using a stable loss function (MSELoss), and preprocessing input data to handle NaN values by replacing them with 0. The code also provides an example of setting stride and kernel size in a convolutional layer and suggests additional techniques like input normalization, weight initialization, and reviewing custom layer implementations. Debugging tips are provided, including printing intermediate values and implementing gradient clipping to prevent exploding gradients. The code emphasizes adapting these strategies and debugging techniques to specific deep learning models and datasets.
import torch
import torch.nn as nn
# Example model definition
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.linear = nn.Linear(10, 1)
def forward(self, x):
return self.linear(x)
# Sample data with potential NaN values
data = torch.tensor([[1.0, 2.0, float('nan'), 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0]])
# 1. Addressing Exploding Gradients and Learning Rate
model = SimpleModel()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) # Reduced learning rate
# 2. Handling Loss Function Issues
loss_fn = nn.MSELoss() # Example: Using a numerically stable loss function
# 3. Input Data Preprocessing
data = torch.nan_to_num(data, nan=0.0) # Replace NaN values with 0
# 4. Stride and Kernel Size (Example for a convolutional layer)
conv_layer = nn.Conv1d(in_channels=1, out_channels=16, kernel_size=3, stride=2) # Stride <= kernel_size
# 5. Other Potential Causes
# - Normalize input data if necessary
# - Experiment with weight initialization: torch.nn.init.xavier_uniform_(model.linear.weight)
# - Review custom layer implementations
# Training loop with debugging tips
for epoch in range(10):
# ... (Load data in batches)
optimizer.zero_grad()
outputs = model(data)
loss = loss_fn(outputs, target) # Calculate loss
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")
# Debugging: Print intermediate values
# print("Activations:", model.linear(data))
# print("Gradients:", model.linear.weight.grad)
loss.backward()
# Gradient Clipping
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)
optimizer.step()Explanation:
1e-4 to prevent large weight updates.nn.MSELoss() is used as a numerically stable loss function.torch.nan_to_num() replaces NaN values in the input data with 0.stride <= kernel_size.torch.nn.utils.clip_grad_norm_() to prevent exploding gradients.Remember to adapt these examples and debugging techniques to your specific deep learning model and dataset.
General Considerations:
NaN values might arise from hardware issues (e.g., faulty GPU). Consider testing your code on a different setup.Data-Specific Issues:
NaN loss. Employ techniques like oversampling, undersampling, or weighted loss functions.Advanced Techniques:
NaN values. Employ it cautiously.Beyond Debugging:
Key Takeaway: Addressing NaN loss is often an iterative process. By understanding the common causes, using the debugging tips, and considering the additional notes, you'll be well-equipped to tackle this challenge effectively.
Encountering NaN (Not a Number) loss during deep learning training can be a common yet frustrating experience. This table summarizes common causes and solutions:
| Cause | Problem | Solution |
|---|---|---|
| Exploding Gradients & Learning Rate | High learning rate leads to excessively large weight updates and gradients, resulting in NaN values. |
Reduce the learning rate (e.g., lr=1e-4 or smaller in your optimizer). |
| Loss Function Issues | Loss function might produce undefined values (e.g., log(0)) for certain inputs. |
Double-check your loss function implementation for edge cases. Consider using a more numerically stable variant. |
| Input Data Problems |
NaN values in training data propagate through calculations. |
Thoroughly check data loading and preprocessing. Replace or remove NaN values in your dataset. |
| Stride and Kernel Size Mismatch | In convolutional layers, stride larger than kernel size can cause issues. | Ensure stride is less than or equal to kernel size. |
| Other Potential Causes | ||
| - Large or zero values in data | Normalize input data to a reasonable range (e.g., 0 to 1). | |
| - Incorrect weight initialization | Experiment with different initialization techniques. | |
| - Numerical instability in custom layers | Review custom layer implementations for potential NaN sources. |
Debugging Tips:
NaN values first appear.torch.nn.utils.clip_grad_norm_).Remember, resolving NaN loss often requires a combination of code inspection, data analysis, and hyperparameter experimentation.
In conclusion, encountering NaN loss during deep learning training can be resolved by addressing common causes such as exploding gradients, loss function issues, input data problems, and stride and kernel size mismatch. Solutions include reducing the learning rate, using stable loss functions, preprocessing data to handle NaN values, and ensuring stride is less than or equal to kernel size. Debugging techniques like reducing batch size, printing intermediate values, and using gradient clipping can help pinpoint the source of the issue. Remember to adapt these strategies to your specific model and dataset for effective resolution.
 python - NaN loss when training regression network - Stack Overflow | May 14, 2016 ... There is very little reason to use SGD with momentum anymore unless you're a neural network fiend and know how to tune the learning schedule.
python - NaN loss when training regression network - Stack Overflow | May 14, 2016 ... There is very little reason to use SGD with momentum anymore unless you're a neural network fiend and know how to tune the learning schedule. I don't understand why I am getting NaN loss scores. Can anyone ... | Posted by u/brike3 - 6 votes and 17 comments
I don't understand why I am getting NaN loss scores. Can anyone ... | Posted by u/brike3 - 6 votes and 17 comments Nan Loss coming after some time - PyTorch Forums | The loss function is a combination of Mean Sqaured error loss and cross-entropy loss. When i am training my model, there is a finite loss but after some time, the loss is NaN and continues to be so. When I am training my model just on a single batch of 10 images, the loss is finite most of the times, but sometimes that is also NaN. Please suggest a possible solution. Thanks in advance
Nan Loss coming after some time - PyTorch Forums | The loss function is a combination of Mean Sqaured error loss and cross-entropy loss. When i am training my model, there is a finite loss but after some time, the loss is NaN and continues to be so. When I am training my model just on a single batch of 10 images, the loss is finite most of the times, but sometimes that is also NaN. Please suggest a possible solution. Thanks in advance What can be the reason of loss=nan and accuracy = 0 in an ML ... | Aug 11, 2021 ... The common reason for loss going to Nan can be loss value getting too big such that it crosses the limit of float.
What can be the reason of loss=nan and accuracy = 0 in an ML ... | Aug 11, 2021 ... The common reason for loss going to Nan can be loss value getting too big such that it crosses the limit of float. Training loss is nan when using ssd to train deep learning model | hello, I am trying to train a ssd model following the guide of this lesson "Use deep learning to assess palm tree health"(https://learn.arcgis.com/en/projects/use-deep-learning-to-assess-palm-tree-health/) . I tried many times with different tile size like 448/128/256/224, different argis pro vers...
Training loss is nan when using ssd to train deep learning model | hello, I am trying to train a ssd model following the guide of this lesson "Use deep learning to assess palm tree health"(https://learn.arcgis.com/en/projects/use-deep-learning-to-assess-palm-tree-health/) . I tried many times with different tile size like 448/128/256/224, different argis pro vers... Training Loss is NaN, Deep Learning - MATLAB Answers - MATLAB ... | Hey everyone!
I am making a neural network in Matlab and I have a database with a lot of zeros (which are NaN values that I had to convert into zeros to be able to run the program), the thing is t...
Training Loss is NaN, Deep Learning - MATLAB Answers - MATLAB ... | Hey everyone!
I am making a neural network in Matlab and I have a database with a lot of zeros (which are NaN values that I had to convert into zeros to be able to run the program), the thing is t...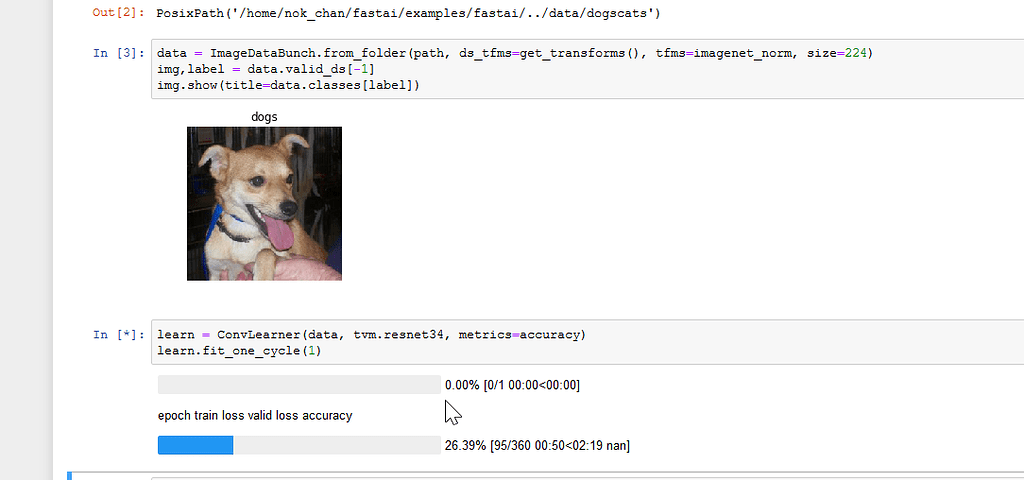 Fastai examples dogscats NaN Loss - fastai dev - fast.ai Course ... | I have asked this in other categories yesterday, but I think here maybe the more appropriate place. I got NaN Loss when running through the example, in fastai/example/dogscats.ipynb. I am running this with the Google Deep Learning Image with latest git pull, and I have checked the library is pulling from the directory (so it is the updated version instead of the pip one) Please remove my previous blog if needed.
Fastai examples dogscats NaN Loss - fastai dev - fast.ai Course ... | I have asked this in other categories yesterday, but I think here maybe the more appropriate place. I got NaN Loss when running through the example, in fastai/example/dogscats.ipynb. I am running this with the Google Deep Learning Image with latest git pull, and I have checked the library is pulling from the directory (so it is the updated version instead of the pip one) Please remove my previous blog if needed.